Магия бюджетирования: как мы разрабатывали модель машинного обучения для задач бюджетирования, и что из этого вышло
Ведущий программист с 10-летним стажем работы с 1С и опытом работы с машинным обучением рассказывает о работе над уникальным инструментом, помогающим финансистам с прогнозированием прибыли в организациях.
Для начала давайте разберемся, что такое машинное обучение (МО), в чем его преимущества и недостатки.
Многие применяют термин «искусственный интеллект», но я считаю, что данный термин малосодержательный (то есть не совсем понятно, что он значит). Термин «машинное обучение» имеет конкретное значение. Методы машинного обучения применяются в тех случаях, когда для решения задачи невозможно подобрать алгоритм, либо когда алгоритм очень сложен с вычислительной точки зрения.
Например, методы машинного обучения часто применяются в задачах компьютерного зрения и распознавания рукописного текста. Ведь невозможно придумать четкий алгоритм, который будет из массива числовых значений пикселей изображения вычленять области, соответствующие, допустим, лицам людей. Но методы машинного обучения можно применять и в других областях, например, в учете и финансах. Машинное обучение в данных областях решает задачи быстрого расчета и прогнозирования.
Так как же работает машинное обучение?
Модель машинного обучения — это специального вида математическая функция, которая должна аппроксимировать искомую зависимость (мы помним, что вид зависимости нам не известен, либо очень сложен, но мы понимаем, что зависимость есть). У этой функции есть большое количество параметров. Количество параметров может быть от нескольких десятков до миллионов и миллиардов. Для того, чтобы модель могла спрогнозировать данные с достаточной точностью, параметры её необходимо настроить – найти для них оптимальные значения.
В процессе настройки параметров используются исторические данные. Это процесс называется обучением модели. Для обучения моделей придуманы специальные математические алгоритмы. После того как модель обучена, ее можно использовать для расчета и прогнозирования. В общем, никакой магии тут нет. Есть только специальные математические функции и алгоритмы.
С какими проблемами мы столкнулись при разработке модели машинного обучения для задач бюджетирования и как их решали
Начну со сбора и обработки данных. В учебных примерах данные для обучения модели обычно представлены в более или менее подготовленном виде. А вся предварительная обработка данных заключается в поиске недостоверных значений и поиске зависимостей между различными признаками. В реальности выборку данных для обучения модели пришлось компоновать самим. Дело в том, что в бюджетной модели значения по каждой статье хранятся в разных строках, также в разных строках хранятся данные по различным значениям аналитики.
Для модели машинного обучения необходимо, чтобы в одной строке были данные сразу по всем статьям и всем аналитикам, от которых зависит выходное значение.
Пример: возьмем бюджетную модель, где данные введены помесячно. Мы создаем модель для расчета показателя прибыли. Нам известно, что в бюджетной модели прибыль зависит от цены на продукцию (по всей аналитике), и от расходов, а также от расходов в предыдущем месяце. Все эти данные изначально хранятся в базе 1с (используем как источник данных) в различных строках (см. таблицы 1 и 2). Соответственно необходимо скомпоновать различные строки в одну. Для языка программирования python разработаны библиотеки, сильно упрощающие работу с данными.
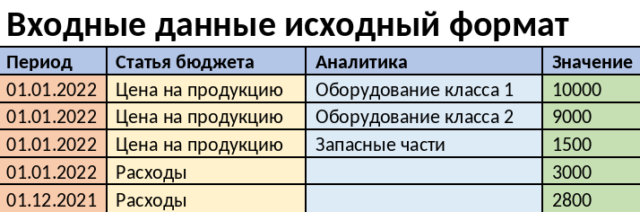
Таблица 1. Пример входных данных в исходном формате
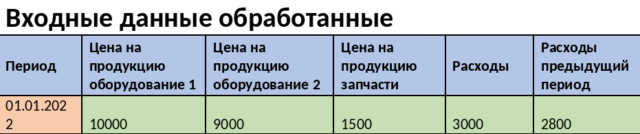
Таблица 2. Пример входных данных после обработки
Проблема 1: недостаток данных
На первый взгляд, данных в бюджетной модели много, но после компоновки и отбрасывания недостоверных значений остается всего несколько сот строк данных (конечно, все зависит от размера базы данных).
Но не стоит отчаиваться. Даже при недостатке данных мы поможем получить приемлемый результат.
Проблема 2: недостоверные, неполные данные или данные разных диапазонов
Выяснилось, что на качество обучения модели влияют ошибки в данных. Каждая ошибка, каждое нерассчитанное значение ухудшает качество обучения модели. По поводу разных диапазонов можно сказать следующее. У меня был пример – данные по одному из ЦФО (центр финансовой ответственности) по одной из статей бюджета данные были по ошибке введены в 1000 раз большими, чем нужно. Все подчиненные данные были корректно посчитаны, и мне казалось, что все должно работать, ведь все зависимости сохранены. Но на самом деле модель МО хорошо работает только в некотором диапазоне данных. А небольшие порции данных, резко выходящие за диапазон остальных данных, очень снижают качество обучения модели.
Следовательно, перед разработкой моделей машинного обучения необходимо очень тщательно проверять данные. Для этого обязательно нужно привлекать специалистов в предметной области (в нашем случае в бюджетировании).
Какие модели выбрать?
Теперь перейдем к вопросу выбора модели. Я начал исследование с линейной модели. Предварительное исследование данных показало, что большинство зависимостей действительно линейные. Пример линейной зависимости f(x, y) = a*x + b*y +c. Для таких зависимостей применима линейная модель. Но иногда встречаются зависимости f(x, y, a) = a*x + b*y +c, где входными данными кроме x, y также является a. Такая зависимость уже не является линейной (смотри рисунки 1 и2). В итоге в качестве модели МО была выбрана нейронная сеть. Хотя для некоторых случаев я вернулся к линейной модели.

Сравнивая нейронную сеть и квадратичную модель можно сказать, что квадратичная модель в отличие от нейронной сети работает не для всех зависимостей бюджетной модели, но там где она работает, она может выдать более точный прогноз на большем диапазоне изменений входных значений.
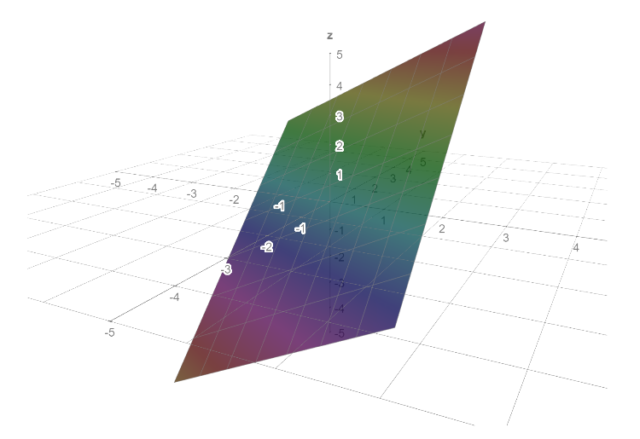
Рисунок 1. Линейная зависимость z = x + 2y
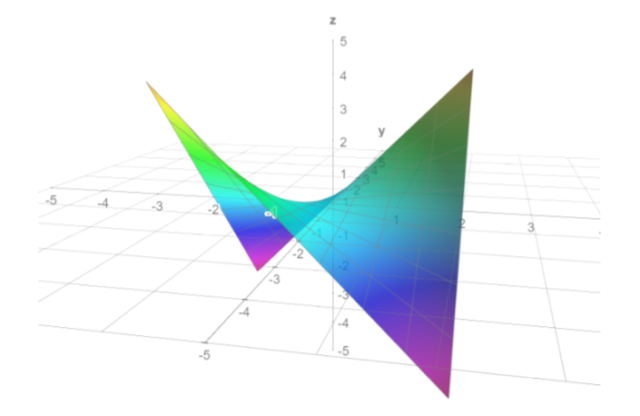
Рисунок 2. Нелинейная зависимость z = xy
Кроме самой модели МО пришлось программировать всю обвязку. Мы развернули сервер на ОС linux. Далее на сервере был развернут http сервис, который взаимодействует со службой, выполняющей код на языке python. Также на данном сервере была установлена СУБД Mongo DB. В базе данных на данной СУБД хранятся настройки модуля, логи, сохраненные и обученные модели и данные для обучения. Был написан код для взаимодействия БД, моделей, обработки входных и выходных данных, логирования.
Но вернемся к самим моделям МО. Одним из преимуществ методов МО является скорость. Самой затратной по времени является обучение модели. В нашем модуле обучение вынесено в отдельные фоновые процессы. Работа с обученной моделью требует секунды времени (взамен часов и дней при непосредственном расчете по формуле). Большая скорость расчета обеспечивается самой структурой модели.
Но, кроме того, несмотря на то, что код моделей у нас написан на языке python, библиотеки для МО во многом написаны на C, C++ (известно, что код на python работает медленнее чем на C, C++). Также некоторые библиотеки могут использовать видеокарту для расчетов.
Проблема 3: критерии качества предсказания моделей
Также есть проблема критериев качества. Есть отдельная теория для расчета различных коэффициентов, характеризующих качество обучения модели. Мы выбрали средний процент ошибки в качестве критерия качества. Но также осталась проблема – какое значение процента ошибки считать минимально достаточным? Скорее всего это должно быть требованием заказчика. Интересно то, что качество модели падает, если входные данные сильно отличаются по значениям от тех данных, на которых обучалась модель. Соответственно можно определить диапазон применимости модели (см. рисунки 3 и 3.1).
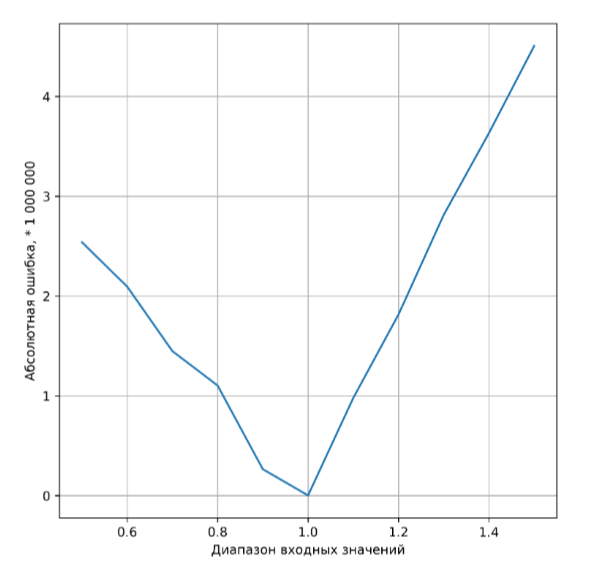
Рисунок 3. Сравнение данных, рассчитанных моделью и тестовых данных
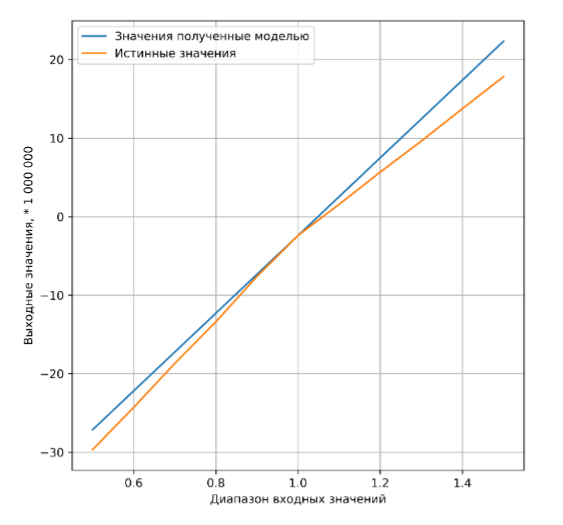
Рисунок 3.1. Изменение абсолютной ошибки в зависимости от входного значения
Здесь также можно сказать, что качество одной и той же модели МО может отличаться в зависимости от того, изменение какого входного показателя мы исследуем. Выяснилось, что если для конкретного входного показателя (например, показатель «Количество продаж») в данных, используемых для обучения, много различных значений, то качество модели большом диапазоне изменения этого показателя хорошее (см. рис. 4, 5).
Если по какому-либо показателю мало различных значений в данных обучения (например, показатель «Скидка продаж»), то есть в истории бюджетной модели значение этого показателя редко менялось, то диапазон изменений этого показателя, при котором модель выдает хороший прогноз небольшой. Фактически в этом случае модель выдает хороший прогноз только по тем данных, по которым она обучалась.
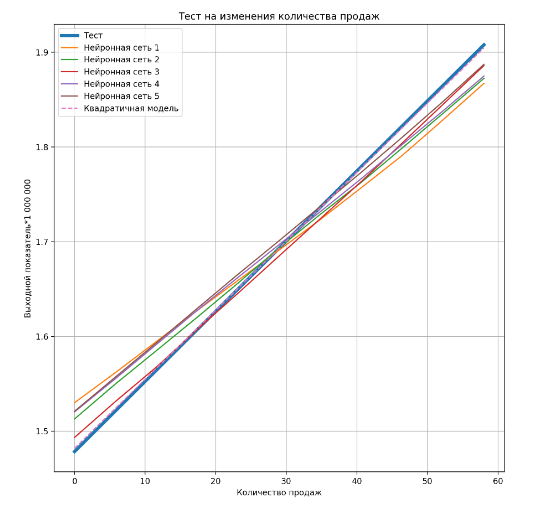
Рисунок 4. Тест прогноза различных моделей при изменении количества продаж
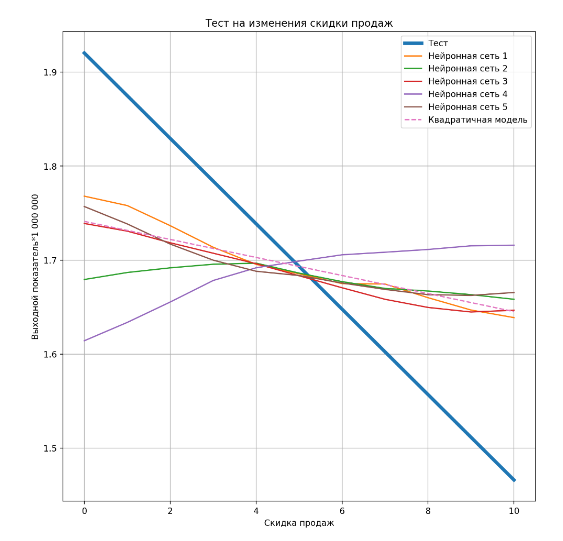
Рисунок 5. Тест прогноза различных моделей при изменении скидки продаж
Есть еще одна особенность поведения моделей машинного обучения на данных бюджетирования. Есть некоторые показатели, которые мало влияют на выходные данные. Средняя абсолютная и относительная ошибка по таким показателям небольшая, но в этом случае может не сохраняться тренд (по прогнозу при изменении значений такого показателя выходные значения могут увеличиваться, а истинные уменьшаться). Это является допустимым, так как в этом случае истинный диапазон изменения выходного показателя и диапазон изменения прогнозного значения меньше погрешности модели (то есть почти 0).
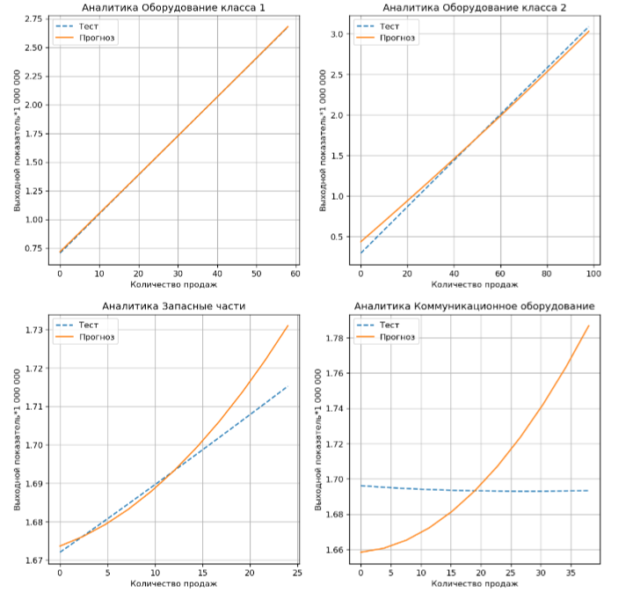
Рисунок 6. Тест прогноза модели по различным аналитикам. По аналитикам «Запасные части», «Коммуникационное оборудование» изменение выходного показателя близко к нулю
Плюсы и минусы машинного обучения
Резюмируя, хочу еще раз сказать о преимуществах и недостатках методов машинного обучения.
Плюсы:
- скорость вычисления в режиме эксплуатации
- модели МО находят скрытые, неочевидные и трудно формализуемые зависимости. Соответственно есть возможность посчитать то, что не удается посчитать иными методами.
Минусы:
- трудности с выбором конкретных моделей МО
Самое главное — это отсутствие порядка в данных.
Машинное обучение применяется в различных областях, но бизнес пока готовится к применению ML. Тратьте минимум времени и получайте наилучшие результаты для принятия важных решений с помощью VBM.
| Автор статьи — Павел Зюзь Ведущий программист офис NFP компании Первый Бит |
Получите демо-стенд по продукту VBM |




























